Using the Structure Prediction tool#
This tutorial shows you how to use the Structure Prediction tool to visualize the 3D structures of your protein sequences using our web app. Structure prediction can also be accessed via the REST API or our Python client.
What you need before getting started#
You need a sequence of interest.
Selecting your model#
We recommend using:
AlphaFold2 is a structure prediction model that builds and samples an MSA to improve accuracy. Use it when accuracy is more important than speed.
Boltz-1 is a high-accuracy model for predicting static 3D structures of biomolecular complexes, including proteins, DNA, and RNA, with accuracy comparable to AlphaFold3. Use it for complex modeling where a static structure is sufficient.
Boltz-2 is a biomolecular structure model that expands on Boltz-1 by supporting dynamic structural ensembles, allowing it to model how proteins, RNA, DNA, and ligands move and interact over time. Use it when dynamic behavior matters.
ESMFold is a fast single-sequence structure prediction model. Use it when speed is more important than accuracy.
ESMFold2 is a high-accuracy structure prediction model for protein monomers and complexes, including antibody-antigen interactions, with optional MSA support. Use it when accuracy is the priority and MSA context may help.
ESMFold2-Fast is a speed-optimized version of ESMFold2 for single-sequence prediction. Use it for high-throughput screening and large-scale design campaigns where speed is the priority.
MiniFold is a fast single-sequence structure prediction model built on ESM-2, delivering accuracy comparable to ESMFold with 10–20× faster inference. Use it for rapid prediction of large numbers of single-chain proteins.
RosettaFold-3 is a three-track neural network for protein structure and complex prediction. Use it for modeling protein-protein interactions or supporting experimental structure determination.
Protenix is a structure prediction model for proteins, DNA, RNA, and small molecule ligands, including their interactions. Use it for multi-molecule complex prediction across diverse molecule types.
Accessing the Structure Prediction tool#
You can access the Structure Prediction tool by selecting Structure Prediction from the top navigation bar, or right-clicking a sequence in your data table.
From the data table#
Right-click a sequence in your data table, then select Fold sequence. This opens the New Structure Prediction page. The default model is ESMFold. To use AlphaFold2, select AlphaFold2 in the Model type dropdown menu. The sequence you selected in the data table is auto-populated.
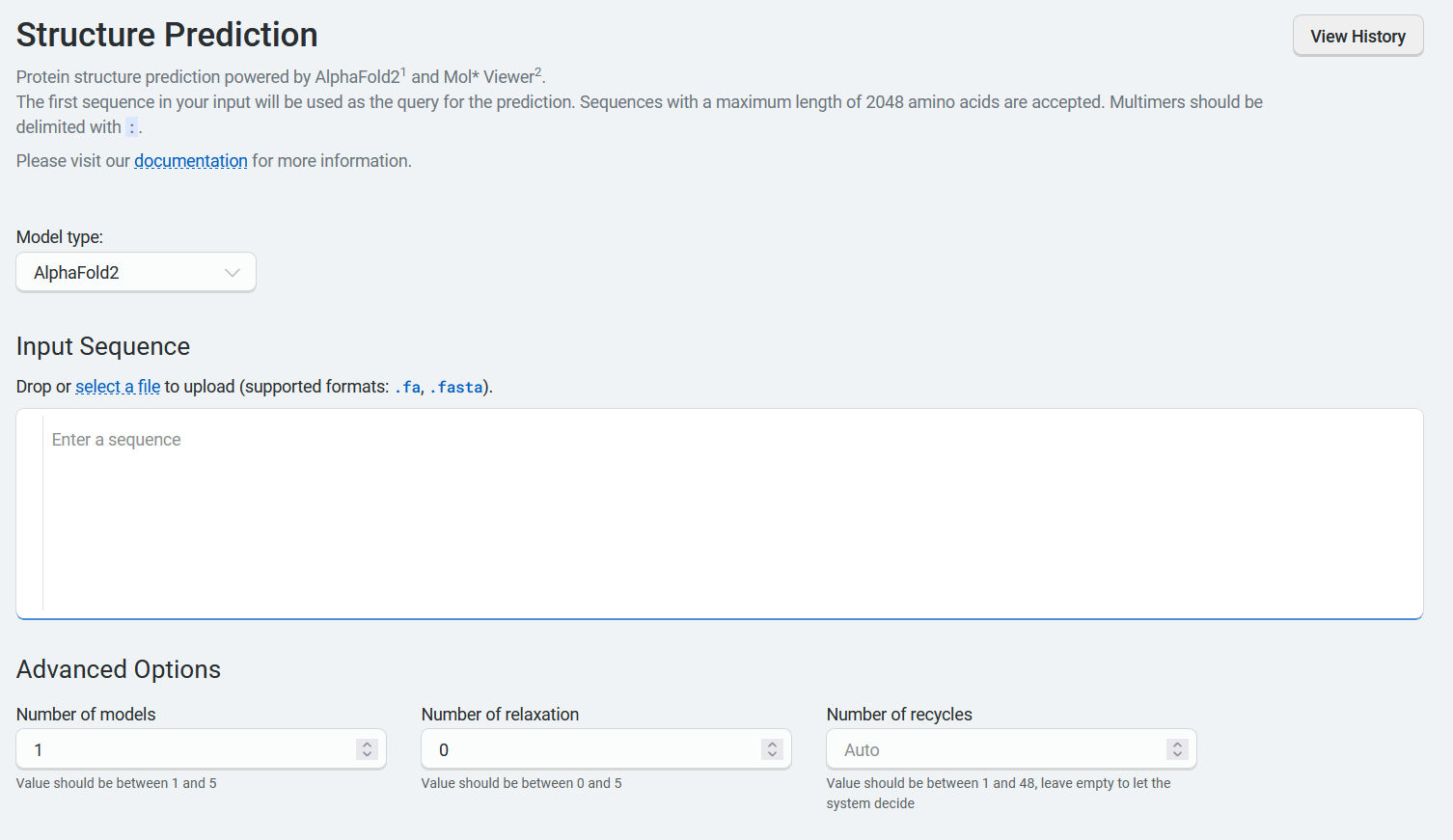
Using AlphaFold2#
If you select AlphaFold2, the Advanced Options section contains several parameters:
Number of models allows you to select the number of models to train. This parameter is set to 1 by default, and accepts integers between 1 and 5. If more than 1 model is available, the best model will be used.
Number of relaxation specifies the number of top ranked structures to relax using AMBER. This parameter is set to 0 by default and accepts integers between 0 and 5. Relaxation is an optional final step in protein structure prediction. It can help resolve rare stereochemical violations and clashes by making small adjustments to the structure using gradient descent in the AMBER force field.
Number of recycles allows the network to further refine structures using the previous cycle’s output as the new cycle’s input. This parameter is set to auto by default and accepts integers between 1 and 48.
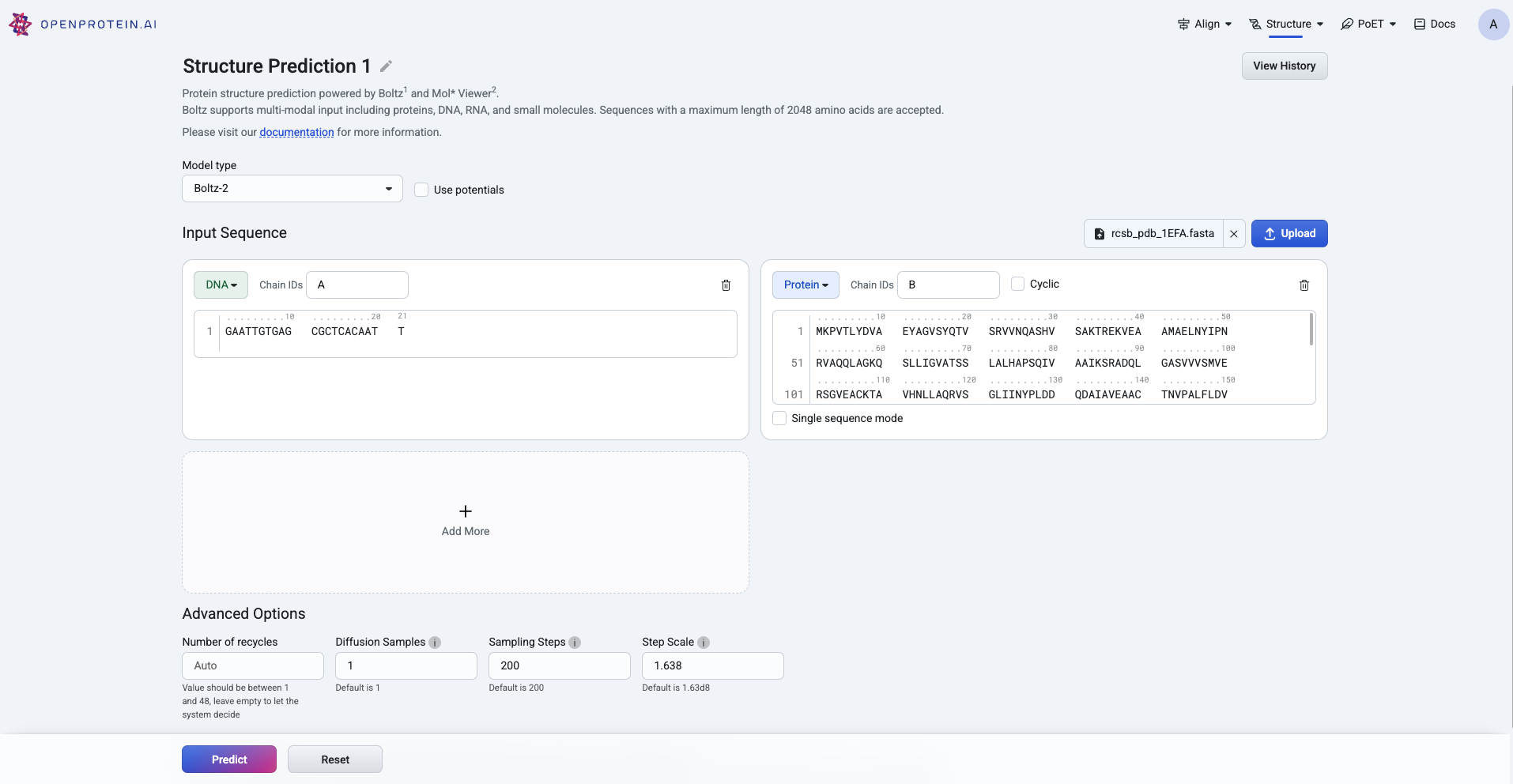
Using Boltz-1 and Boltz-2#
When using Boltz-1 or Boltz-2, you can enter or upload protein, ligand, DNA, or RNA sequences in the input fields provided. Be sure to select the correct sequence type from the dropdown menu.
The Advanced Options section contains several parameters:
Diffusion samples This refers to the number of diffusion samples used and controls how many independent structure samples are generated per input
Sampling steps This sets the number of steps in the diffusion process for each sample
Step scale Adjusts the effective temperature or diversity of teh sampling process. The higher the values, the higher the diversity
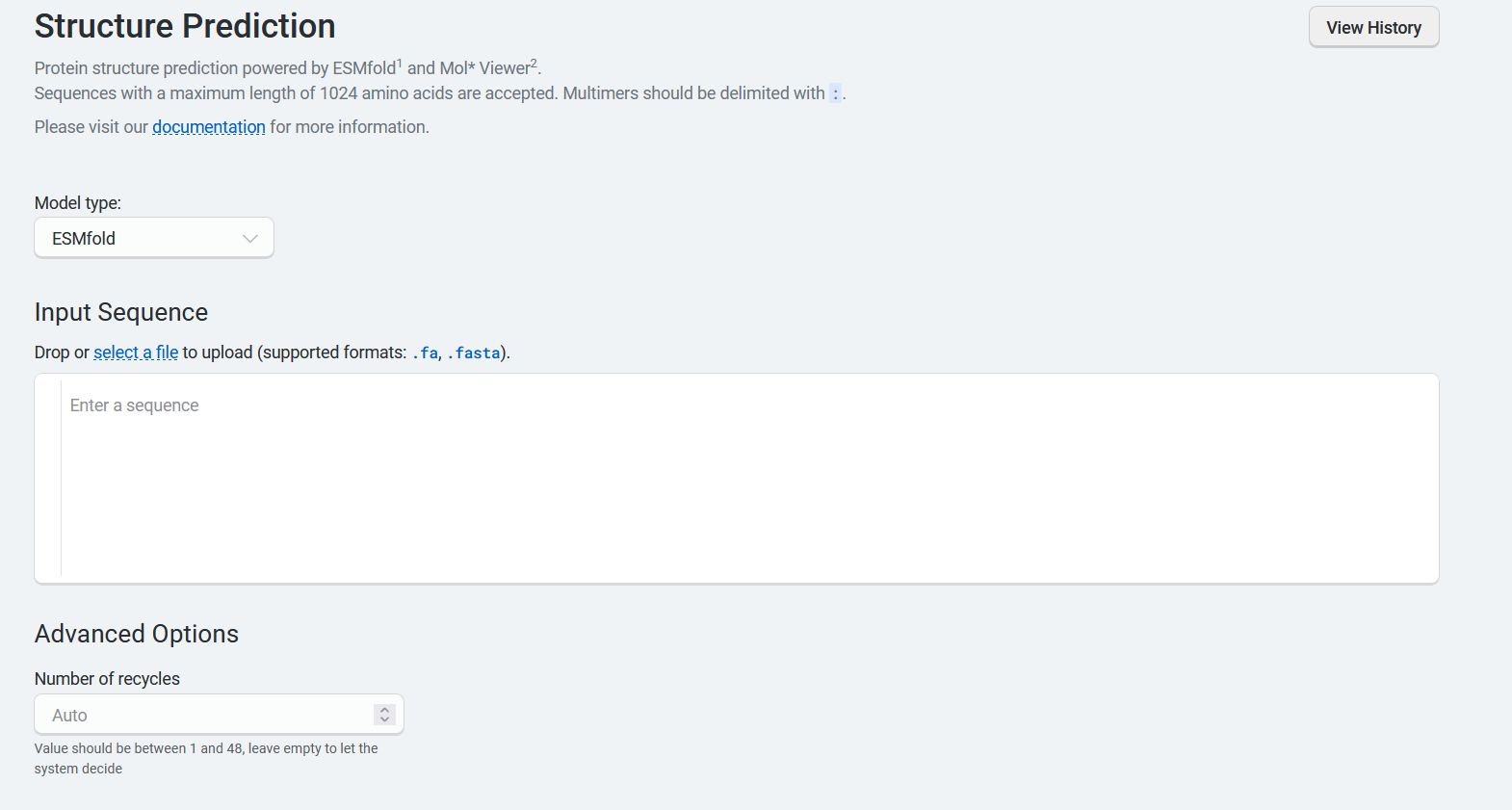
Using ESMFold#
If you select ESMFold, the Advanced Options section allows you to set the Number of recycles. This allows the network to further refine structures by using the previous cycle’s output as the new cycle’s input. This parameter is set to auto by default and accepts integers between 1 and 48.
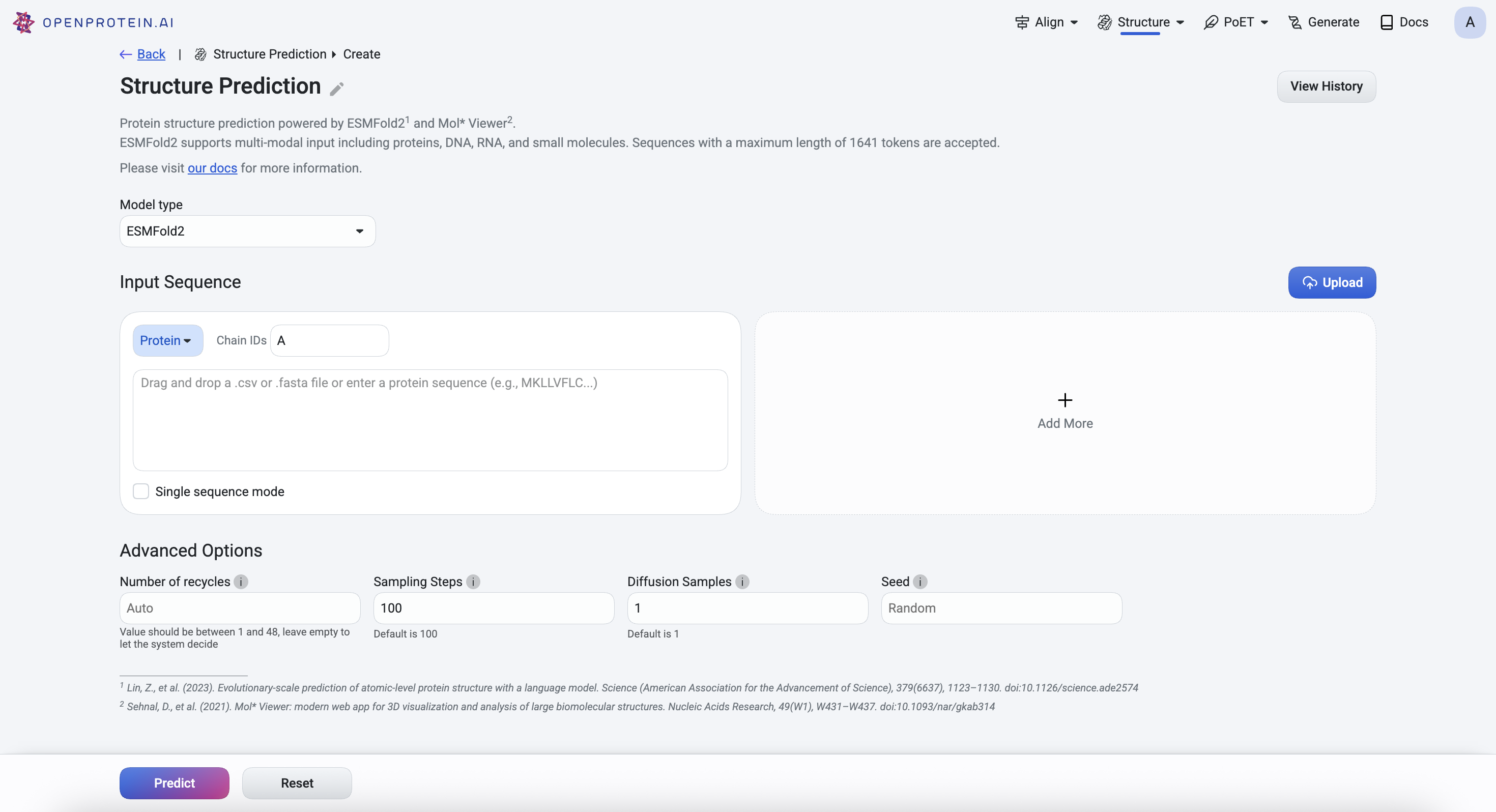
Using ESMFold2 and ESMFold2-fast#
If you select ESMFold2, the Advanced Options section allows you to set the following: - Number of recycles This allows the network to further refine structures by using the previous cycle’s output as the new cycle’s input. This parameter is set to auto by default and accepts integers between 1 and 48. - Diffusion samples This refers to the number of diffusion samples used and controls how many independent structure samples are generated per input - Sampling steps This sets the number of steps in the diffusion process for each sample - Step scale Adjusts the effective temperature or diversity of teh sampling process. The higher the values, the higher the diversity
Using MiniFold#
If you select MiniFold, the Advanced Options let you set the Number of recycles, which controls how many times the network refines a structure by feeding the output of one cycle into the next. This parameter defaults to auto and accepts integers from 1 to 48.
Additional notes: - Supports only single-chain proteins - Maximum sequence length: 2048
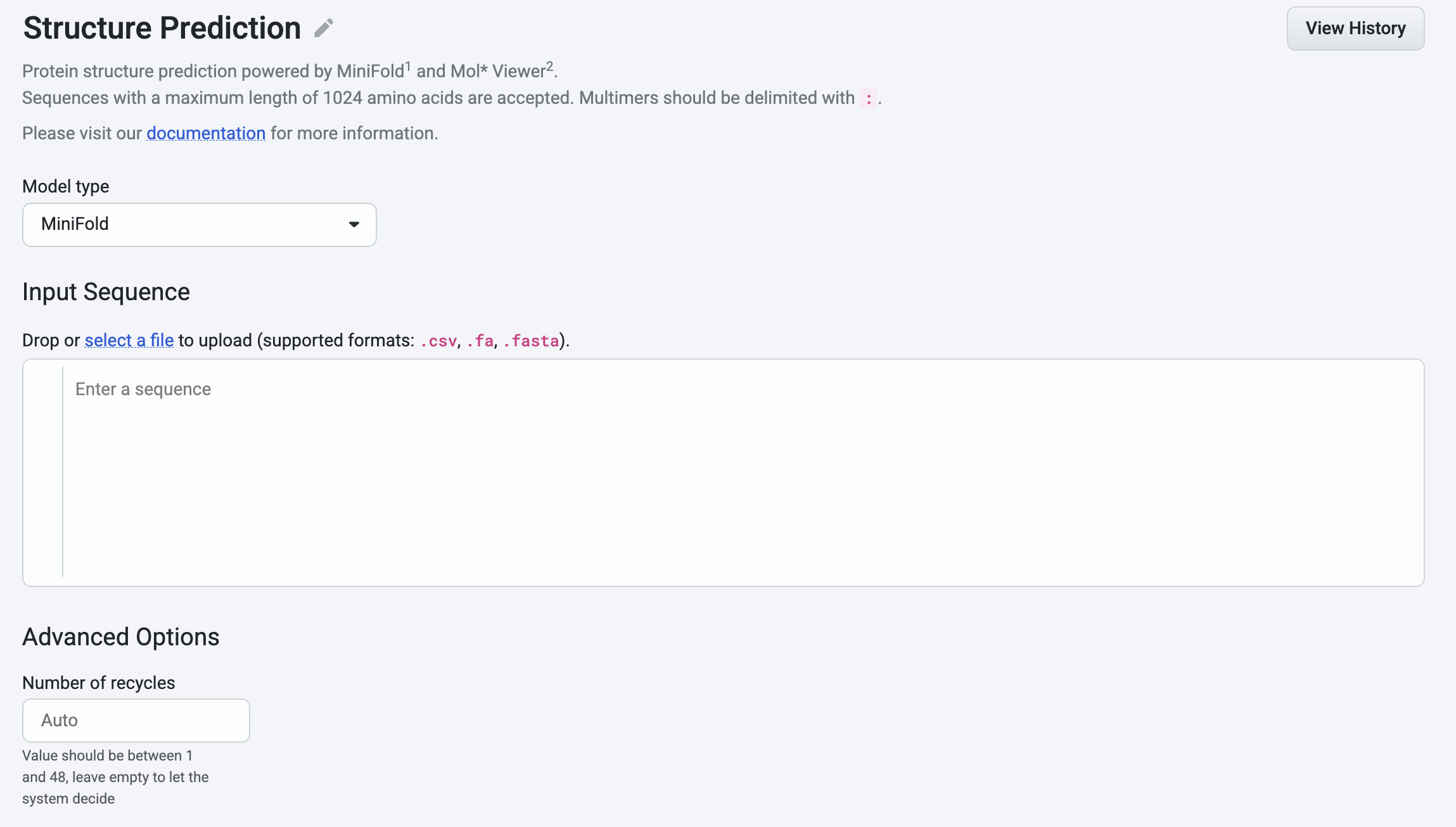
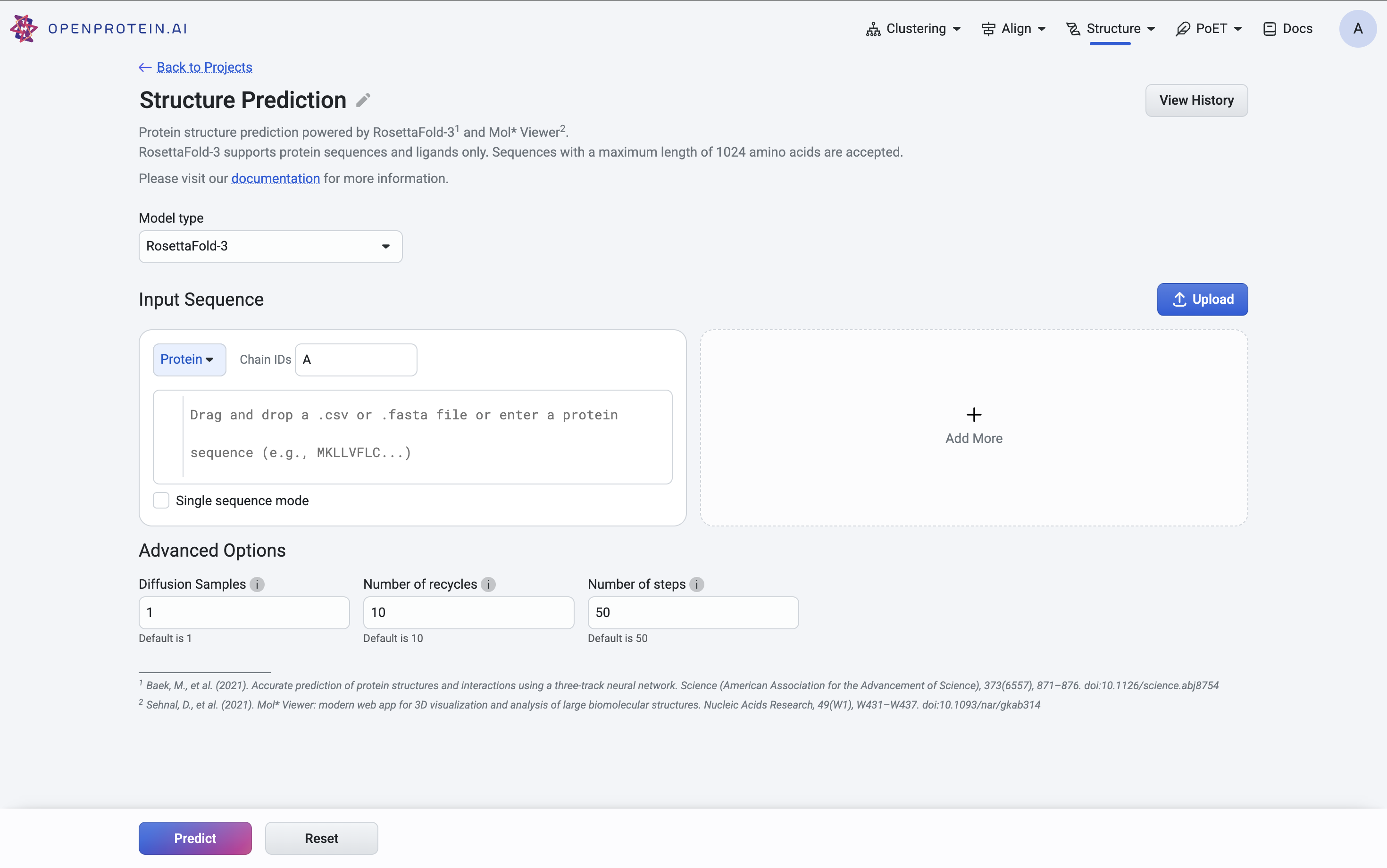
Using RosettaFold-3#
When using RosettaFold-3, you can enter or upload multiple proteins in the input fields provided.
The Advanced Options section contains several parameters:
Diffusion samples This refers to the number of diffusion samples used and controls how many independent structure samples are generated per input
Number of recycles This refers to how many times the model feeds its output structure back into the network for further refinement.
Number of Steps Thisrefers to how many iterations or updates the model performs during inference when predicting a structure
Using Protenix#
When using Protenix, you can enter or upload multiple proteins in the input fields provided.
The Advanced Options section contains several parameters:
Number of recycles Controls how many times the model feeds its predicted structure back into itself for refinement. Higher values improve accuracy but increase computation time.
Diffusion Samples Sets how many independent structure candidates are generated per input. More samples increase the chance of finding the best conformation but proportionally increase runtime.
Sampling Steps Defines the number of denoising steps the diffusion process takes to build each structure. More steps produce more precise, physically valid outputs at the cost of longer inference.
Step Scale Adjusts the sampling temperature, controlling how broadly the model explores structural space. Higher values produce more diverse candidates; lower values give tighter, more consistent results.

Visualizing your sequence#
When you’re ready to visualize your sequence, select Predict.
After the model is finished training, it displays a 3D visualization of the protein structure. You can edit your sequence name by selecting the title box or the pencil icon, and use the available tools to zoom, rotate, and pan through the 3D structure.
A confidence indicator is included as a predicted local distance difference test (pLDDT) score, where a higher score indicates higher confidence in the prediction. Sections of the predicted structure are color coded to correspond with the pLDDT color legend to the right of the structure.
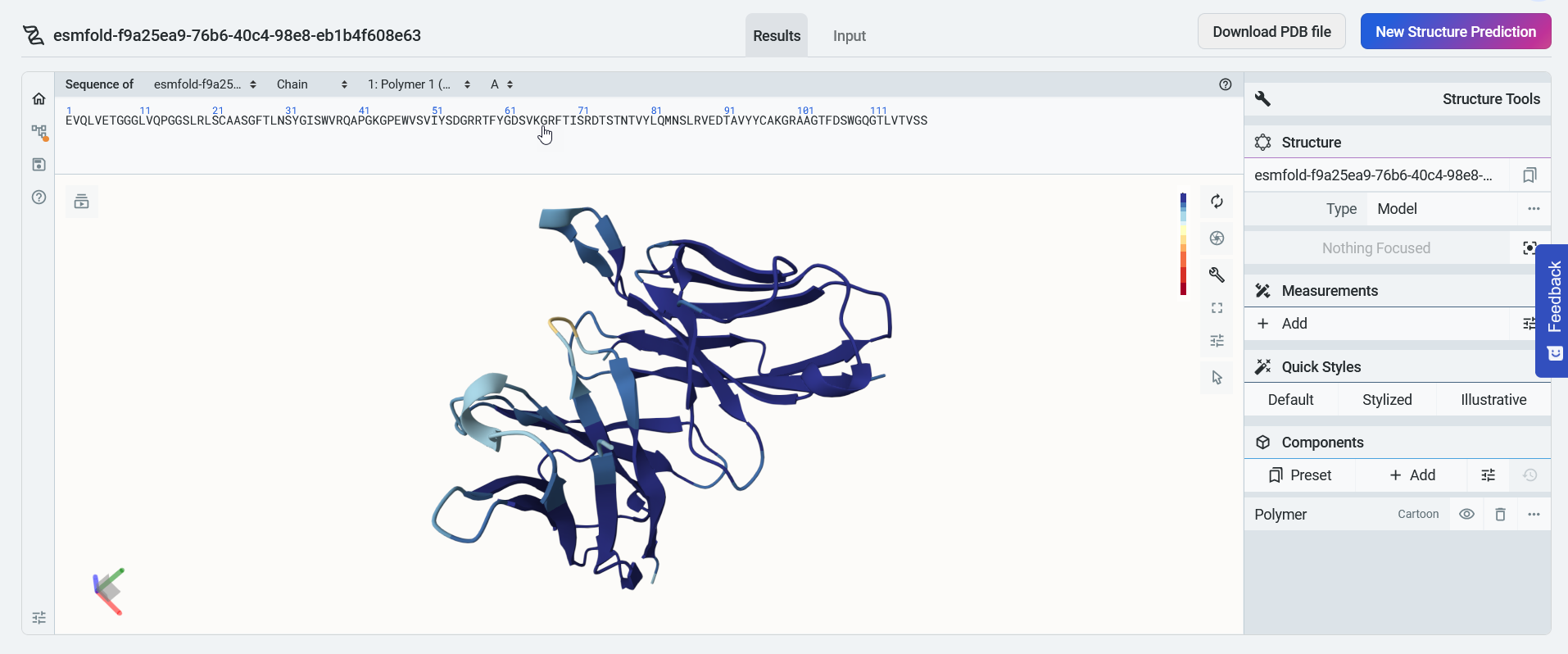
You can select Input to view your design input sequence, or select New structure prediction to start a new prediction.
Comparing structures#
After a 3D structure prediction is complete, you can add existing structures to compare against the predicted model using the Mol* viewer.
Adding structures#
To add a structure to the viewer:
Select the + icon in the left panel
drag and drop a PDB file directly into the viewer
You can add multiple structures for comparison. Each structure appears as a separate entry in the left panel.
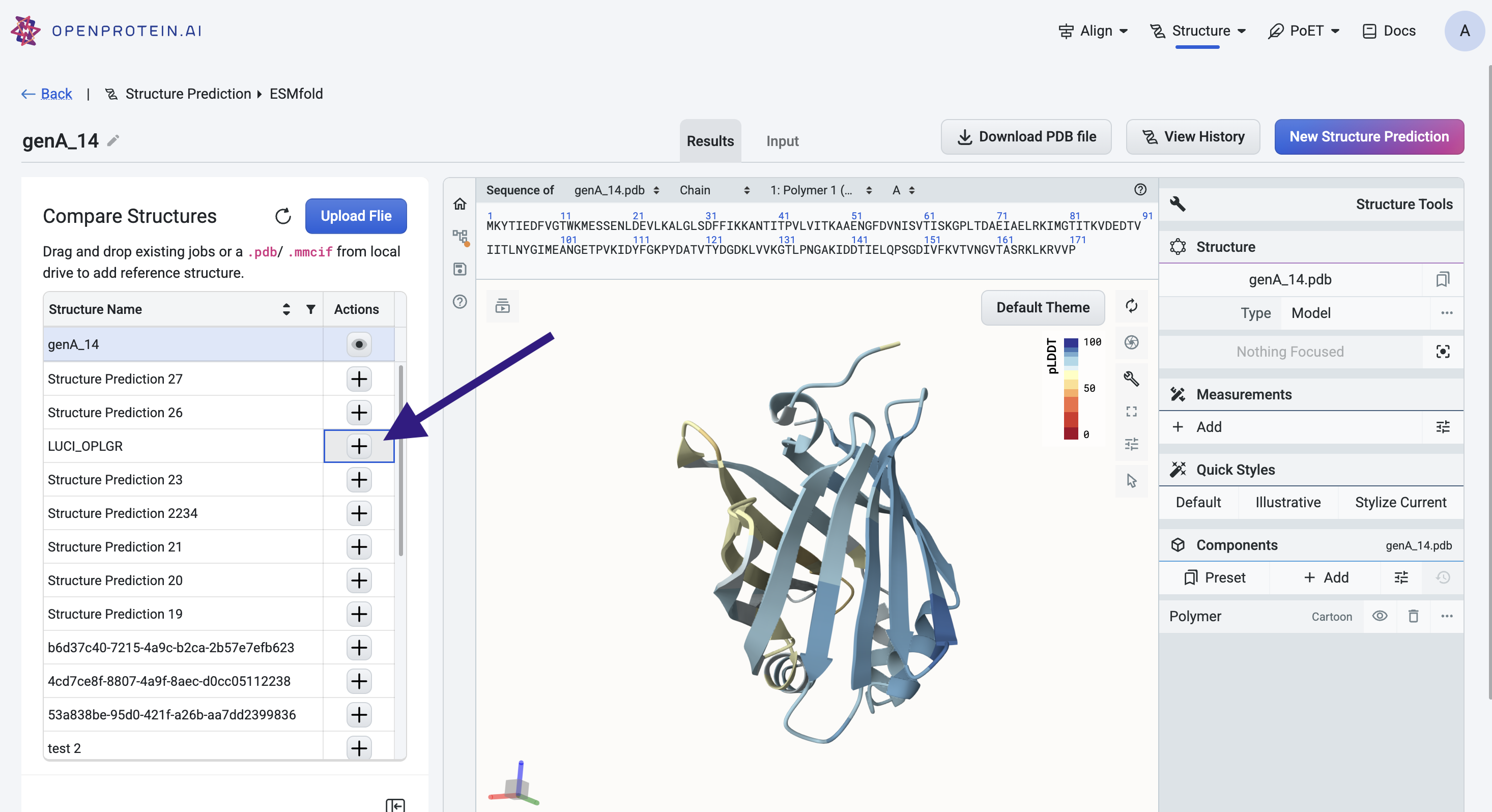
Managing structures#
Use the eye icon next to each structure in the left panel to toggle its visibility. This can help isolate or focus on specific structures in the viewer.
To remove a structure from the viewer entirely, click the trash can icon next to the structure name.
Downloading your 3D structure#
For structure predictions using ESMFold, select Download PDB file to export the 3D structure as a .pdb file.
For structure predictions using AlphaFold2, select Download .mmCIF file.
Accessing previous predictions#
View previously visualized structures by selecting History in the Structure Prediction tool menu. The History tab also contains the following information about your past structure predictions:
job ID
model type
date created